Architecture Overview
The CDCP platform is based on file data. So you can start with a folder of data (the source data) in a specific, simple format, see https://github.com/cambridge-collection/dl-data-samples . We use TEI for item data, JSON / HTML for collection data and TIFF for our image data.
That data is the automatically converted in real time into the processed data, which is easy for the application to read.

See our tei-data-processing-overview for more details on how this is done.
The processed data is read by a number of applications, which provide the functionality for the viewer.

More details can be found on the Solr stack.
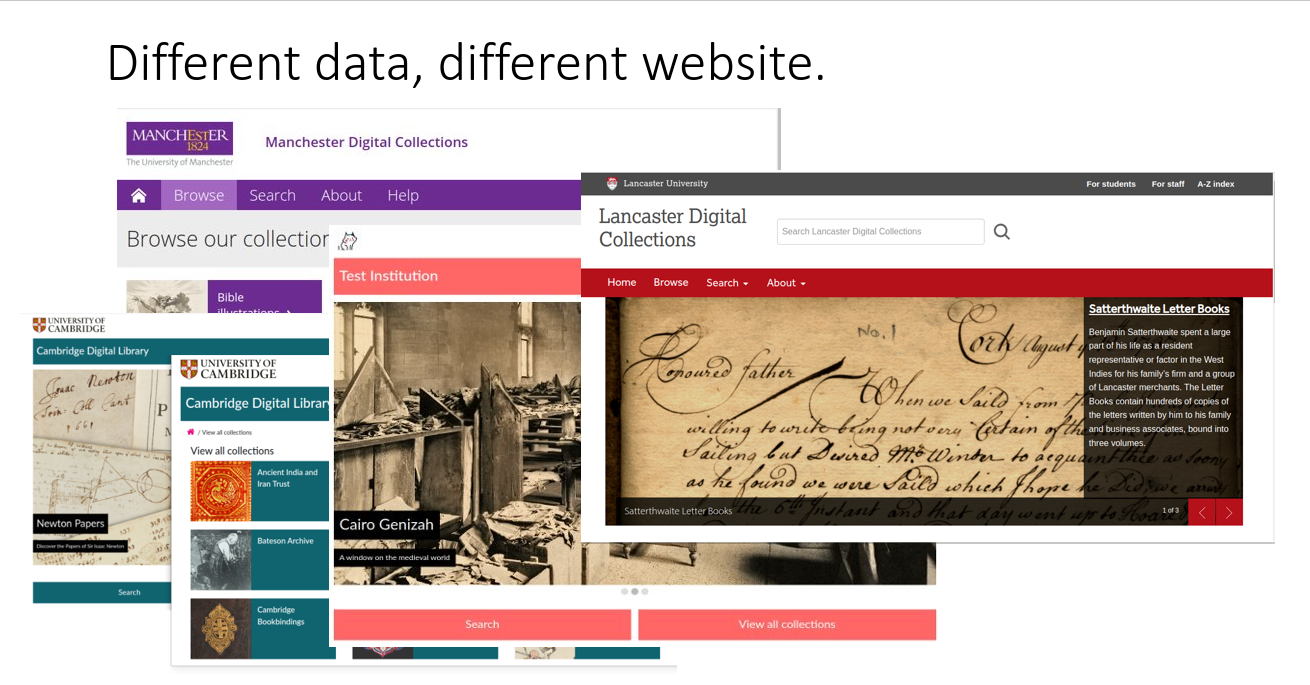
What does the data look like? It has a simple hierarchy and is easy to read JSON data, with item data in TEI. A collection can have multiple items, and items can be in more than one collection.

So you can edit the source data, so have different title and themes, and override the css,
so by just editing the data and not having to recompile the site you can get lots of different looks,
and different collection and item data too.
Getting Started
Have a look at the cudl-viewer repo: https://github.com/cambridge-collection/cudl-viewer and some instructions on setting up a local version of the viewer to try out.
Or if you want to go further and build a full platform on AWS you can take a look at our Terraform instructions.
Optional Enhancements
We also have a content loader which edits the data in the source folder, allowing non-expert users to edit items and collections and these changes are reflected a few seconds later on the processed data + linked viewer website. See our content-editor section for more info.

We also have an extension to the processing flow to allow automatic generation of transcriptions by Transkribus. Code for this is also under our Terraform repository: https://github.com/cambridge-collection/cudl-terraform
